Clustering is a main issue in without supervision artificial intelligence (ML) with lots of applications throughout domains in both market and scholastic research study more broadly. At its core, clustering includes the following issue: offered a set of information aspects, the objective is to partition the information aspects into groups such that comparable items remain in the very same group, while different items remain in various groups. This issue has actually been studied in mathematics, computer technology, operations research study and data for more than 60 years in its myriad variations. 2 typical types of clustering are metric clustering, in which the aspects are points in a metric area, like in the k-means issue, and chart clustering, where the aspects are nodes of a chart whose edges represent resemblance amongst them.
 |
| In the k-means clustering issue, we are offered a set of points in a metric area with the goal to recognize k representative points, called centers (here portrayed as triangles), so regarding reduce the amount of the squared ranges from each indicate its closest center. Source, rights: CC-BY-SA-4.0 |
{kind=link}
In spite of the substantial literature on algorithm style for clustering, couple of useful works have actually concentrated on carefully securing the user’s personal privacy throughout clustering. When clustering is used to individual information (e.g., the inquiries a user has actually made), it is required to think about the personal privacy ramifications of utilizing a clustering service in a genuine system and just how much info the output service exposes about the input information.
To make sure personal privacy in an extensive sense, one service is to establish differentially personal (DP) clustering algorithms. These algorithms make sure that the output of the clustering does not expose personal info about a particular information component (e.g., whether a user has actually made an offered question) or delicate information about the input chart (e.g., a relationship in a social media network). Provided the significance of personal privacy defenses in without supervision artificial intelligence, in the last few years Google has actually purchased research study on theory and practice of differentially personal metric or chart clustering, and differential personal privacy in a range of contexts, e.g., heatmaps or tools to create DP algorithms.
Today we are thrilled to reveal 2 essential updates: 1) a brand-new differentially-private algorithm for hierarchical chart clustering, which we’ll exist at ICML 2023, and 2) the open-source release of the code of a scalable differentially-private k– implies algorithm. This code brings differentially personal k– implies clustering to big scale datasets utilizing dispersed computing. Here, we will likewise discuss our deal with clustering innovation for a current launch in the health domain for notifying public health authorities.
Differentially personal hierarchical clustering
Hierarchical clustering is a popular clustering technique that includes recursively segmenting a dataset into clusters at a significantly finer granularity. A popular example of hierarchical clustering is the phylogenetic tree in biology in which all life in the world is separated into finer and finer groups (e.g., kingdom, phylum, class, order, and so on). A hierarchical clustering algorithm gets as input a chart representing the resemblance of entities and finds out such recursive partitions in a not being watched method. Yet at the time of our research study no algorithm was understood to calculate hierarchical clustering of a chart with edge personal privacy, i.e., maintaining the personal privacy of the vertex interactions.
In “ Differentially-Private Hierarchical Clustering with Provable Approximation Warranties“, we think about how well the issue can be estimated in a DP context and develop company upper and lower bounds on the personal privacy assurance. We create an approximation algorithm (the very first of its kind) with a polynomial running time that attains both an additive mistake that scales with the variety of nodes n (of order n 2.5) and a multiplicative approximation of O( log 1/2 n), with the multiplicative mistake similar to the non-private setting. We even more supply a brand-new lower bound on the additive mistake (of order n 2) for any personal algorithm (irrespective of its running time) and supply an exponential-time algorithm that matches this lower bound. Additionally, our paper consists of a beyond-worst-case analysis concentrating on the hierarchical stochastic block design, a basic random chart design that displays a natural hierarchical clustering structure, and presents a personal algorithm that returns a service with an additive expense over the optimum that is minimal for bigger and bigger charts, once again matching the non-private cutting edge methods. Our company believe this work broadens the understanding of personal privacy maintaining algorithms on chart information and will allow brand-new applications in such settings.
Massive differentially personal clustering
We now change equipments and discuss our work for metric area clustering. Many previous operate in DP metric clustering has actually concentrated on enhancing the approximation warranties of the algorithms on the k– implies unbiased, leaving scalability concerns out of the photo. Undoubtedly, it is unclear how effective non-private algorithms such as k-means++ or k-means// can be made differentially personal without compromising dramatically either on the approximation warranties or the scalability. On the other hand, both scalability and personal privacy are of main significance at Google. For this factor, we just recently released several documents that attend to the issue of developing effective differentially personal algorithms for clustering that can scale to enormous datasets. Our objective is, furthermore, to provide scalability to big scale input datasets, even when the target variety of centers, k, is big.
We operate in the enormously parallel calculation (MPC) design, which is a calculation design agent of modern-day dispersed calculation architectures. The design includes numerous devices, each holding just part of the input information, that interact with the objective of resolving an international issue while decreasing the quantity of interaction in between devices. We provide a differentially personal continuous aspect approximation algorithm for k– implies that just needs a consistent variety of rounds of synchronization. Our algorithm builds on our previous work on the issue (with code offered here), which was the very first differentially-private clustering algorithm with provable approximation warranties that can operate in the MPC design.
The DP continuous aspect approximation algorithm dramatically enhances on the previous work utilizing a 2 stage technique. In a preliminary stage it calculates an unrefined approximation to “seed” the 2nd stage, which includes a more advanced dispersed algorithm. Geared up with the first-step approximation, the 2nd stage counts on arise from the Coreset literature to subsample a pertinent set of input points and discover an excellent differentially personal clustering service for the input points. We then show that this service generalizes with around the very same assurance to the whole input.
Vaccination search insights through DP clustering
We then use these advances in differentially personal clustering to real-world applications. One example is our application of our differentially-private clustering service for releasing COVID vaccine-related inquiries, while offering strong personal privacy defenses for the users.
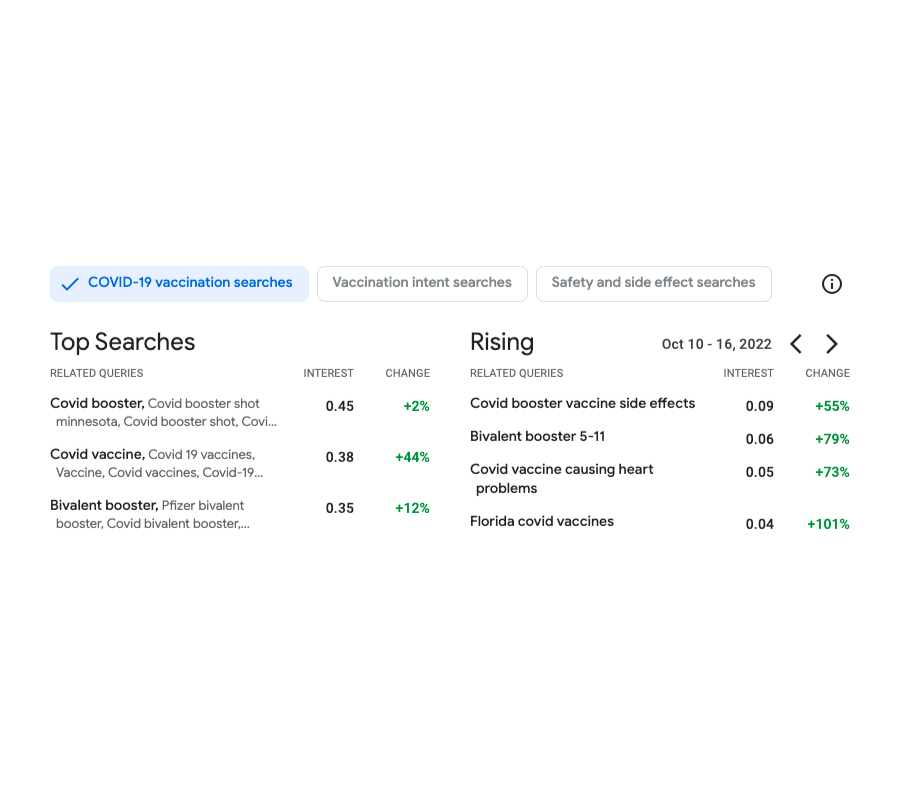
The objective of Vaccination Browse Insights (VSI) is to assist public health choice makers (health authorities, federal government firms and nonprofits) recognize and react to neighborhoods’ info requires relating to COVID vaccines. In order to attain this, the tool enables users to check out at various geolocation granularities (zip-code, county and state level in the U.S.) the leading styles browsed by users relating to COVID inquiries. In specific, the tool pictures data on trending inquiries increasing in interest in an offered location and time.
 |
| Screenshot of the output of the tool. Shown left wing, the leading searches connected to Covid vaccines throughout the duration Oct 10-16 2022. On the right, the inquiries that have actually had increasing significance throughout the very same duration and compared to the previous week. |
To much better assistance determining the styles of the trending searches, the tool clusters the search inquiries based upon their semantic resemblance. This is done by using a custom-made k– ways– based algorithm run over search information that has actually been anonymized utilizing the DP Gaussian system to include sound and get rid of low-count inquiries (hence leading to a differentially clustering). The approach makes sure strong differential personal privacy warranties for the defense of the user information.
This tool supplied fine-grained information on COVID vaccine understanding in the population at extraordinary scales of granularity, something that is particularly pertinent to comprehend the requirements of the marginalized neighborhoods disproportionately impacted by COVID. This task highlights the effect of our financial investment in research study in differential personal privacy, and without supervision ML approaches. We are wanting to other essential locations where we can use these clustering methods to assist guide choice making around international health obstacles, like search inquiries on environment modification– associated obstacles such as air quality or severe heat.
Recognitions
We thank our co-authors Silvio Lattanzi, Vahab Mirrokni, Andres Munoz Medina, Shyam Narayanan, David Saulpic, Chris Schwiegelshohn, Sergei Vassilvitskii, Peilin Zhong and our associates from the Health AI group that made the VSI launch possible Shailesh Bavadekar, Adam Boulanger, Tague Griffith, Mansi Kansal, Chaitanya Kamath, Akim Kumok, Yael Mayer, Tomer Shekel, Megan Shum, Charlotte Stanton, Mimi Sun, Swapnil Vispute, and Mark Young.
To learn more on the Chart Mining group (part of Algorithm and Optimization) go to our pages.