
( Warm_Tail/ Shutterstock)
Business that discover themselves not able to get the answer out of conventional analytical databases rapidly enough to please their efficiency requirements might wish to have a look at an emerging class of real-time analytical databases. As one of the leading members of this brand-new class, Apache Druid is discovering fans amongst the most advanced customers, consisting of Salesforce and Confluent.
Cloud information storage facilities like Google Huge Inquiry, Snowflake, and Amazon Redshift have actually changed the economics of huge information storage and introduced a brand-new age of innovative analytics. Business all over the world that could not pay for to develop their own scale-out, column-oriented analytical databases, or who simply didn’t desire the trouble, might lease access to a huge cloud information storage facility with virtually limitless scalability.
However as transformational as these cloud information storage facilities, information lakes, and information lakehouses have actually been, they still can not provide the SQL question efficiency required by a few of the greatest business on earth.
If your requirement consists of evaluating petabytes’ worth of real-time occasion information integrated with historic information, getting the response back in less than a 2nd, and doing this simultaneously countless times per 2nd, you discover that you rapidly surpass the technical ability of the conventional information storage facility.
Which’s where you discover yourself going into the world of a brand-new class of database. The folks at Imply, the business behind the Apache Druid task, call it a real-time analytics database, however other attires have various names for it.
David Wang, vice president of item marketing at Imply, states Druid sits at the crossway of analytics and applications.![]()
” Analytics constantly represented massive aggregations and group-bys and huge filtered questions, however applications constantly represented a work that suggests high concurrency on functional information. It needs to be truly, truly quick and interactive,” he states. “There is this crossway point on the Venn diagram that, when you’re attempting to do genuine analytics, however do it at the speed, the concurrency, and the functional nature of occasions, then you have actually got to have something that’s function developed for that crossway. And I believe that’s where this classification has actually emerged.”
Druid’s Deepest, Darkest Tricks
Apache Druid was initially produced in 2011 by 4 engineers at Metamarkets, a designer of programmatic marketing options, to power complex SQL analytics atop big quantities of high dimensional and high cardinality information. Among the Druid co-authors, Fangjin Yang, went on to co-found and act as CEO Imply, and he is likewise a Datanami Individual to See for 2023.
There’s no single secret active ingredient in Druid that makes it so quick, Wang states. Rather, it’s a mix of abilities established over years that enable it to do things that conventional databases simply can’t do.
” It has to do with CPU effectiveness,” Wang states. “What we do under the covers is we have actually an extremely enhanced storage format that leverages this truly distinct method to how we do division and partitioning, in addition to how we really keep the information. It’s not simply columnar storage, however we utilize dictionary encoding, bit-mapped indexing, and other algorithms that enable us to truly reduce the quantity of rows and quantity of columns that really need to be examined. That makes a substantial effect in regards to efficiency.”
The separation of calculate and storage has actually ended up being standard procedure in the cloud, as it makes it possible for business to scale them separately, which conserves cash. The tradeoff in loss of efficiency by separating calculate and storage and positioning information in item shops is appropriate in lots of utilize cases. However if you’re grabbing the upper reaches of analytics efficiency on huge, fast-moving information, that tradeoff is no longer practical.
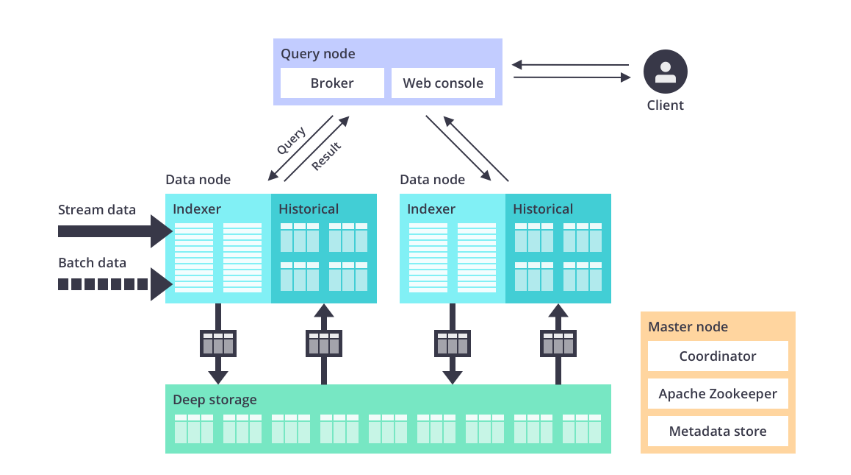
Apache Druid’s architecture (Image source: Apache Druid)
” You can’t get the sort of [high] efficiency if you do not have actually information structured in a specific manner in which drives the effectiveness of the processing,” Wang states. “We absolutely think that, for the truly quick questions, where you’re truly attempting to drive interactivity, you have actually got to do standard things, like do not move information. If you’re going to need to move information from item storage into you’re the calculate nodes at question time you’re getting a struck on network latency. That’s simply physics.”
Druid in Action
The SQL analytic offerings from Snowflake, Redshift, and Databricks stand out at serving conventional BI reports and control panels, Wang states. Druid is serving a various class of user with a various work.
For instance, Salesforce‘s engineering group is utilizing Druid to power its edge intelligence system, Wang states. Item supervisors, website dependability engineers (SREs), and different advancement groups are utilizing Druid to examine various elements of the Salesforce cloud, consisting of efficiency, bugs, and triaging concerns, he states.
” It’s all ad-hoc. They’re not predefining the questions in advance of what they’re trying to find. It’s not pre-cached. It’s all on-the-fly pivot tables that are being produced off of trillions of rows of information and they’re getting instantaneous actions,” Wang states. “Why is Salesforce doing that? It’s due to the fact that the scale of their occasion information is at a size that they require an actually quick engine to be able to process it rapidly.”
Even if a standard information storage facility might consume the actual time information rapidly enough, it could not power the number concurrent questions to support this kind of usage case, Wang states.
” We’re not attempting to combat Snowflake or Databricks or any of these people, due to the fact that our work is simply various,” he states. “Snowflake’s optimum concurrency is 8. Your greatest scale-up virtual information storage facility can support 8 concurrent questions. You can cluster like 8 or 10, so you get 80 QPS[queries per second] We have clients that run POCs that have countless QPS. It’s a various ballgame.”

( vecktor/Shutterstock)
‘ Spinning Wheel of Death’
Confluent has a comparable requirement to monitor its cloud operations. The business that utilizes the primary specialists in the Apache Kafka message bus chosen Druid to power a facilities observability offering that’s utilized both internally (by Confluent engineers) in addition to externally (exposed to Confluent clients).
According to Wang, their information requirements were enormous. Confluent required an analytics database that might consume 5 million occasions per 2nd and provide subsecond question action time throughout 350 channels concurrently (350 QPS). Rather of utilizing their own item (ksqlDB) or a streaming information system (Confluent just recently got an Apache Flink professional and is establishing a Flink offering), they selected Druid.
Confluent, which blogged about its usage of Druid, chosen Druid due to its capability to query both real-time and historic information, Wang states.
” There is a basic distinction in between a stream processor and an analytic database,” he states. “If you’re attempting to simply do a predefined question on a constant stream, then a stream procedure is going to be rather enough there. However if you’re attempting to do actual time analytics, taking a look at real-time occasions relatively with historic information, then you require to have a consistent information keep that supports both actual time information in addition to historic information. That’s why you require an analytics database.”
Momentum is developing for Druid, Wang states. More than 1,400 business have actually put Druid into action, he states, consisting of business like Netflix, Target, Cisco’s ThousandEyes, and significant banks. Petabyte-scale implementations including countless nodes are not unusual. Indicate itself has actually been pressing advancement of its cloud-based Druid service, called Polaris, and more brand-new functions are anticipated to be revealed next month.
As awareness of real-time analytics databases constructs, business discover Druid is a great suitable for both brand-new information analytics tasks, in addition to existing tasks that required a bit more analytics muscle. Those roadways ultimately result in Druid and Imply, Wang states.
” When we’re speaking with designers about the analytic tasks, we inquired, hey, exist any usage cases where efficiency and scale matter? Where they attempted to develop an analytic application utilizing … a various database and they struck that scale constraint, where they struck the spinning wheel of death since that architecture wasn’t created for these kind of aggregations at the volume and the concurrency requirements?” he states. “And after that we open a discussion.”
Associated Products:
Imply Raises $100M Series D to Make Developers the Heroes of Analytics
Apache Druid Shapeshifts with New Inquiry Engine
Yahoo Casts Real-Time OLAP Queries with Druid